Create dataframe from RDD and table from dataframe
from pyspark import SparkContext, SparkConf,HiveContext
%sql
Employee=[(1,"jonny","2000","sales"),
(2,"jack","4000","finance"),
(3,"dinarys","3000","acc"),
(4,"john","5000","hr"),
(5,"theon","3000","sales"),
(6,"bran","5000","finance"),
(7,"john","2000","acc"),
(8,"sansa","2000","hr")]
EmployeeRDD=sc.parallelize(Employee)
EmployeeDF=sqlContext.createDataFrame(EmployeeRDD).toDF('Eid','Emp_Name','Emp_Salary','Dept')
EmployeeDF.registerTempTable('EmployeeTB')
result1=sqlContext.sql("select * from EmployeeTB limit 3")
result1.show()
1.Avg()
Average function with partition data
ResultAvg=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,avg(Emp_salary) over (partition by Dept ) as AvgSal from EmployeeTB")
ResultAvg.show()








from pyspark import SparkContext, SparkConf,HiveContext
%sql
Employee=[(1,"jonny","2000","sales"),
(2,"jack","4000","finance"),
(3,"dinarys","3000","acc"),
(4,"john","5000","hr"),
(5,"theon","3000","sales"),
(6,"bran","5000","finance"),
(7,"john","2000","acc"),
(8,"sansa","2000","hr")]
EmployeeRDD=sc.parallelize(Employee)
EmployeeDF=sqlContext.createDataFrame(EmployeeRDD).toDF('Eid','Emp_Name','Emp_Salary','Dept')
EmployeeDF.registerTempTable('EmployeeTB')
result1=sqlContext.sql("select * from EmployeeTB limit 3")
result1.show()
1.Avg()
Average function with partition data
ResultAvg=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,avg(Emp_salary) over (partition by Dept ) as AvgSal from EmployeeTB")
ResultAvg.show()

2.Sum()
Sum function will give sum of values witin partition or order by row of values
Sum without partition of values
ResultSum=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,sum(Emp_Salary) over(order by Emp_Salary desc) as SumSal from EmployeeTB")
ResultSum.show()
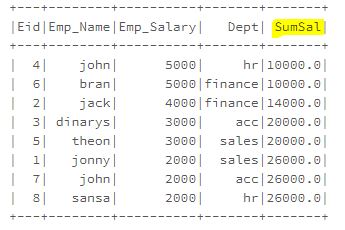
Sum with partition
ResultSum1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,sum(Emp_Salary) over(partition by Dept order by Emp_Salary desc) as SumSal from EmployeeTB")
ResultSum1.show()
This gives more logical and accurate nad meaningful sum of values for every row within dept partition.

3.Min()
This will return minimum value for every row within partition.
Min without partition
ResultMin1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,min(Emp_Salary) over(order by Emp_Salary) as MinSal from EmployeeTB")
ResultMin1.show()

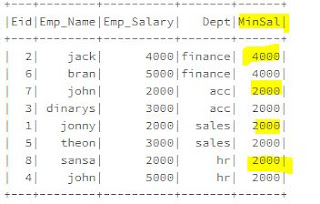
Min with partition
ResultMin=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,min(Emp_Salary) over(partition by Dept order by Emp_Salary) as MinSal from EmployeeTB")
ResultMin.show()

4.max()
max will return maximum of values within the order by or partition clause
max without partition
ResultMax=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,max(Emp_Salary) over(order by Emp_Salary) as MaxSal from EmployeeTB")
ResultMax.show()

max with partition
ResultMax1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,max(Emp_Salary) over(partition by Dept) as MaxSal from EmployeeTB")
ResultMax1.show()

5.count()
count will return count of values witin the order by or partition by clause
count without partition
ResultCount=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,count(*) over(order by Emp_Salary ) as Count from EmployeeTB")
ResultCount.show()

count with partition
ResultCount1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,count(*) over(partition by Dept order by Emp_Salary ) as Count from EmployeeTB")
ResultCount1.show()




No comments:
Post a Comment