Important analytical rank window functions
1.rank()
2.dense_rank()
3.percent_rank()
4.row_number()
Create Dataframe from RDD, Create Temp Table from Data frame
from pyspark import SparkContext, SparkConf,HiveContext
%sql
Employee=[(1,"jonny","2000","sales"),
(2,"jack","4000","finance"),
(3,"dinarys","3000","acc"),
(4,"john","5000","hr"),
(5,"theon","3000","sales"),
(6,"bran","5000","finance"),
(7,"john","2000","acc"),
(8,"sansa","2000","hr")]
EmployeeRDD=sc.parallelize(Employee)
EmployeeDF=sqlContext.createDataFrame(EmployeeRDD).toDF('Eid','Emp_Name','Emp_Salary','Dept')
EmployeeDF.registerTempTable('EmployeeTB')
result1=sqlContext.sql("select * from EmployeeTB limit 3")
result1.show()
1.rank()
The RANK window function determines the rank of a value in a group of values.
Each value is ranked within its partition.
The ORDER BY expression in the OVER clause determines the value.
Ranks might not be consecutive numbers.
Rows with equal values for the ranking criteria receive the same rank.
Rank function without partition
rankresult=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, rank() over (order by Emp_Salary desc) as rank from EmployeeTB")
rankresult.show()
 Rank function with partition
Rank function with partition
rankresult1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, rank() over (partition by Dept order by Emp_Salary desc) as rank from EmployeeTB")
rankresult1.show()







1.rank()
2.dense_rank()
3.percent_rank()
4.row_number()
Create Dataframe from RDD, Create Temp Table from Data frame
from pyspark import SparkContext, SparkConf,HiveContext
%sql
Employee=[(1,"jonny","2000","sales"),
(2,"jack","4000","finance"),
(3,"dinarys","3000","acc"),
(4,"john","5000","hr"),
(5,"theon","3000","sales"),
(6,"bran","5000","finance"),
(7,"john","2000","acc"),
(8,"sansa","2000","hr")]
EmployeeRDD=sc.parallelize(Employee)
EmployeeDF=sqlContext.createDataFrame(EmployeeRDD).toDF('Eid','Emp_Name','Emp_Salary','Dept')
EmployeeDF.registerTempTable('EmployeeTB')
result1=sqlContext.sql("select * from EmployeeTB limit 3")
result1.show()
1.rank()
The RANK window function determines the rank of a value in a group of values.
Each value is ranked within its partition.
The ORDER BY expression in the OVER clause determines the value.
Ranks might not be consecutive numbers.
Rows with equal values for the ranking criteria receive the same rank.
Rank function without partition
rankresult=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, rank() over (order by Emp_Salary desc) as rank from EmployeeTB")
rankresult.show()
rankresult1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, rank() over (partition by Dept order by Emp_Salary desc) as rank from EmployeeTB")
rankresult1.show()

2.dense_rank()
The DENSE_RANK () window function determines the rank of a value in a group of values based on the ORDER BY expression and the OVER clause.
Each value is ranked within its partition.
Rows with equal values receive the same rank.
There are no gaps in the sequence of ranked values if two or more rows have the same rank.
dense_rank without partition
rankresult=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, dense_rank() over (order by Emp_Salary desc) as denserank from EmployeeTB")
rankresult.show()

dense_rank with partition
rankresult1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, dense_rank() over (partition by Dept order by Emp_Salary desc) as DenseR from EmployeeTB")
rankresult1.show()

3.percent_rank()
The PERCENT_RANK () window function calculates the percent rank of the current row using the following formula: (x - 1) / (number of rows in window partition - 1)
where x is the rank of the current row.
percent_rank without partition
rankresult=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, percent_rank() over (order by Emp_Salary desc) as percentR from EmployeeTB")
rankresult.show()

percent_rank with partition
rankresult=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept, percent_rank() over (partition by Dept order by Emp_Salary desc) as percentR from EmployeeTB")
rankresult.show()

4.row_number()
The ROW_NUMBER window function determines the ordinal number of the current row within its partition.
The ORDER BY expression in the OVER clause determines the number.
Each value is ordered within its partition.
Rows with equal values for the ORDER BY expressions receive different row numbers nondeterministically.
row_number without partition
RESULT2=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,row_number() over(order by Emp_Name)as RowNo from EmployeeTB")
RESULT2.show()
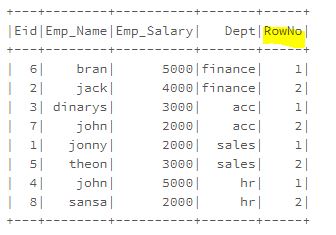
row_number with partition
RESULT1=sqlContext.sql("select Eid,Emp_Name,Emp_Salary,Dept,row_number() over(partition by Dept order by Emp_Name)as RowNo from EmployeeTB")
RESULT1.show()




No comments:
Post a Comment