Narrow transformations are the result of map, filter and such that is from the data from a single partition
An output RDD has partitions with records that originate from a single partition in the parent RDD. Only a limited subset of partitions used to calculate the result.
Transformations with (usually) Narrow dependencies:
mapmapValuesflatMapfiltermapPartitionsmapPartitionsWithIndex

Wide Transformations: In wide transformation, all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD. The partition may live in many partitions of parent RDD. Wide transformations are the result of groupbyKey() and reducebyKey().
Each partition of the parent RDD may be used by multiple child partitions
Transformations with (usually) Wide dependencies: (might cause a shuffle)
cogroupgroupWithjoinleftOuterJoinrightOuterJoingroupByKeyreduceByKeycombineByKeydistinctintersectionrepartitioncoalesce

1.map()
The map function iterates over every line in RDD and split into new RDD. Using map() transformation we take in any function, and that function is applied to every element/line of RDD.
from pyspark import SparkContext,SparkConf
FileA=sc.textFile("/FileStore/tables/file1.txt")
FileB=sc.textFile("/FileStore/tables/file2.txt")
FileC=sc.textFile("/FileStore/tables/file3.txt")
FileAB=FileA.union(FileB)
FileABC=FileAB.union(FileC)
FileABCflatten=FileABC.map(lambda x:x.split(" "))
FileABCflatten.collect()

Here, each word within line gets separated by spaces and considered into a tuple, as shown by square brackets.
2.flatMap()
flatMap() function, to each input element, we have many elements in an output RDD. The most simple use of flatMap() is to split each input string into words.
from pyspark import SparkContext,SparkConf
FileA=sc.textFile("/FileStore/tables/file1.txt")
FileB=sc.textFile("/FileStore/tables/file2.txt")
FileC=sc.textFile("/FileStore/tables/file3.txt")
FileAB=FileA.union(FileB)
FileABC=FileAB.union(FileC)
FileABCflatten=FileABC.flatMap(lambda x:x.split(" "))
FileABCflatten.collect()

Here all words are separated by spaces and put into one list.
What is the difference between map and flatMap?
3.MapPartition
Return a new RDD by applying a function to each partition of this RDD.
Why partition?
Parallelism is the key feature of any distributed system where operations are done by dividing the data into multiple parallel partitions. The same operation is performed on the partitions simultaneously which helps achieve fast data processing with a spark. Map and Reduce operations can be effectively applied in parallel in apache spark by dividing the data into multiple partitions. A copy of each partition within an RDD is distributed across several workers running on different nodes of a cluster so that in case of failure of a single worker the RDD still remains available.
mapPartitions() can be used as an alternative to map() & foreach().
mapPartitions() is called once for each Partition unlike map() & foreach() which is called for each element in the RDD. The main advantage being that, we can do initialization on Per-Partition basis instead of per-element basis(as done by map() & foreach())
from pyspark import SparkContext,SparkConf
def func1(num): yield sum(num)
list1=[1,2,5,3,7,9,2,2]
Rdd1=sc.parallelize(list1,3)
List2=(Rdd1.mapPartitions(func1))
List2.collect()

Return a new RDD by applying a function to each partition of this RDD,
while tracking the index of the original partition
5.Filter
Return a new RDD containing only the elements that satisfy a predicate.
from pyspark import SparkContext,SparkConf
#Filter common words in another file
FileA=sc.textFile("/FileStore/tables/file2.txt")#separate all words by spacesFile1=FileA.flatMap(lambda x:x.split(" ")).flatMap(lambda x:x.split(".")).flatMap(lambda x:x.split(","))#filter common wordsFile2=File1.filter(lambda x:x=='Kafka')File2.collect()#filter words apart from KafkaFile3=File1.filter(lambda x:x!='Kafka')File3.collect()

6.Union()
The union is basically used to merge two RDDs together if they have the same structure.
from pyspark import SparkContext,SparkConf
List1=range(1,20,10)
List2=range(20,40,10)
Rdd1=sc.parallelize(List1)Rdd2=sc.parallelize(List2)
Rdd1.union(Rdd2).collect()

7.intersection()
Intersection gives you the common terms or objects from the two RDDS.
from pyspark import SparkContext,SparkConf
List1=[1,2,4,6,8,90,3,2]
List2=[4,5,6,7,9,2,1,2,90]
Rdd1=sc.parallelize(List1)Rdd2=sc.parallelize(List2)#gives common from both RDD
Rdd1.intersection(Rdd2).collect()

8.distinct()
This transformation is used to get rid of any ambiguities. As the name suggests it picks out the lines from the RDD that are unique.
from pyspark import SparkContext, SparkConf
List1=[1,2,4,6,8,90,3,2]
List2=[4,5,6,7,9,2,1,2,90]
Rdd1=sc.parallelize(List1)Rdd2=sc.parallelize(List2)#gives all from both RDDRdd2=Rdd1.union(Rdd2)#gives distinct from RDDRdd2.distinct().collect()

9.join()
This transformation joins two RDDs based on a common key.
from pyspark import SparkContext,SparkConf
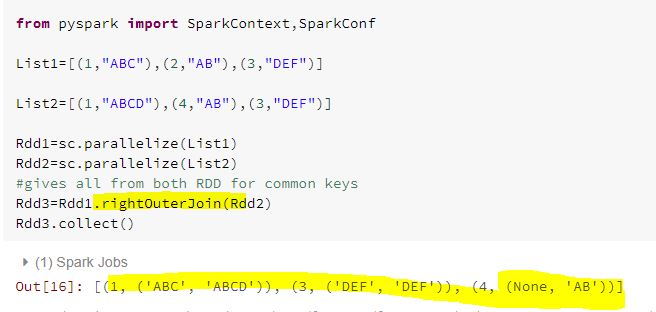
List1=[(1,"ABC"),(2,"AB"),(3,"DEF")]
List2=[(1,"ABCD"),(4,"AB"),(3,"DEF")]
Rdd1=sc.parallelize(List1)Rdd2=sc.parallelize(List2)#gives all from both RDD for common keysRdd3=Rdd1.join(Rdd2)Rdd3.collect()

leftOuterJoin:This gives all from left Rdd and common from right Rdd